
Kaileigh McCrea, Privacy Engineer • 14 minute read

This is the write-up for the research presented at Diana Initiative on August 7, 2023, BSides Las Vegas on August 9, 2023, and BlackHat on August 10, 2023 in Las Vegas.
In late January 2023, almost 45 GB of source code from the Russian search giant Yandex was leaked on BreachForums by a former Yandex employee. While the leak itself did not contain user data, it reportedly contained the source code for all major Yandex services, including Metrika, which collects user analytics through a widely used SDK, and Crypta, Yandex’s behavioral analytics technology.
I got involved when a fellow privacy researcher reached out to verify what he’d found in a different part of the codebase. After spending the week digging around and verifying his findings, on Friday night I sat down with a glass of wine and decided to dig into something I was curious about. While there has been lots of speculation about what Yandex could do with the massive amounts of data it collects, this is the first time outsiders have been able to peek behind the curtain to confirm it, and what I’ve found is both fascinating and deeply unsettling.
Background
Yandex is Russia’s largest search engine and the massive platform has over 90 other services under its umbrella, including a browser, mail service, cloud platform, maps, and smart devices with Alice, Yandex’s smart assistant. The primary services that we are going to be focusing on are AppMetrica, which is Yandex’s app/web analytics service, Crypta, which analyzes user data to identify important user characteristics for generating ad segments, and Audiences, which allows users to pull data from several sources to generate their own targeted segments. Most of Yandex’s services are based in Russia but its parent company, Yandex N.V. is based in The Netherlands.
Yandex: A Drama
In 2019, Yandex granted a “golden share” to the Kremlin-linked Public Interest Foundation (PIF) to “defend the country's interests”. According to The Guardian, Putin has previously expressed concern with “preventing the private data of Russian citizens from falling into foreign hands” and limiting “foreign ownership in strategic tech firms.” The "golden share" gave the PIF “a veto over key company decisions” and the power “to temporarily remove Yandex’s management, block a potential acquisition of the company, and nominate two permanent board members.” The Kremlin has long recognized the importance of Yandex holding vast amounts of Russian user data and has sought to control where it can be sent.
After Russia invaded Ukraine in February, 2022, that dynamic began to flip as Western countries began to express concern about their citizens’ data being sent to Russian servers. Keir Giles, a senior Russia fellow at Chatham House, told The Guardian, “The problem arises when it is a hostile state that wishes to cause us damage and is interested in specific individuals they wish to track in this country…It has the potential to be weaponised against anybody. Do we want, at a time when Russia is considering the UK as an enemy, to be providing all our personal details to a server in Moscow?”
In March 2022, the Financial Times published findings by privacy researcher Zach Edwards that sounded the alarm about Yandex’s AppMetrica SDK sending app analytics data to Yandex servers in Russia. The SDK is reportedly installed in hundreds of millions of apps globally, including VPNs and apps targeting Ukrainian users. Yandex pushed back that they asked users for consent but experts suggested the SDK merely piggy-backed on the consent the app had obtained. According to the article, ‘“Yandex has acknowledged its software collects “device, network and IP address” information … but it called this data “non-personalised and very limited”. It added: “Although theoretically possible, in practice it is extremely hard to identify users based solely on such information collected. Yandex definitely cannot do this.”’
At the same time, TechCrunch reported that Yandex faced increased pressure from the Russian government, through strict media laws, to spread propaganda about war in Ukraine, while its executives faced sanctions from the EU over spreading that disinformation. Jailed opposition leader Alexey Navalny said in a series of very spicy tweets that Yandex’s claim of displaying “News” on its homepage was a “solid shameless lie”. According to an article from MIT Technology Review, at this time, "Some 70% of the information on Yandex News was coming from state-controlled media sources pushing propaganda”. A former Yandex executive, Grigory Bakunov, suggested that Yandex backed itself into this corner by being naive to how the tools they were building could be appropriated and gamed by the Russian government. Yandex, along with other Russian media companies, decided it was smarter to restructure and sell off their politically inconvenient assets.
By April, tens of thousands of engineers, including several of Yandex’s, had fled the country. According to MIT Technology Review, government figures showed that “about 100,000 IT specialists left Russia in 2022, or some 10% of the tech workforce—a number that is likely an underestimate.”
In June, its CEO, Arkady Volozh, stepped down after being targeted by EU sanctions. There does not appear to be a replacement CEO, leaving control of Yandex to its board.
In August, Yandex finally reached a deal to sell its media products News, Zen, and, very surprisingly, the homepage (yandex.ru) to Russian state controlled social media company VK, in exchange for sole ownership of VK’s food delivery app. If you visit yandex.ru now, it redirects to dzen.ru. VK was the obvious potential buyer from the start but the delay in the sale was rumored to be the result of the "golden share", which gave the PIF power to block any potential acquisitions. It’s not clear whether that sale would have included the user data that the News and Zen apps had access to.
In November, Yandex’s Dutch holding/parent company Yandex N.V. announced plans to "divest ownership and control of most of Yandex Group" and "said in a statement it was reviewing options to 'restructure the group's ownership and governance in light of the current geopolitical environment.'" Reuters also reported that Putin and his ally, former Finance Minister Alexei Kudrin, held a late night meeting to discuss the future of Yandex and Kudrin’s potential role in it. In December, Kudrin confirmed that he would be joining Yandex to take on the role of Adviser on Corporate Development, to advise on the restructuring.
In late January 2023, the Yandex source code was leaked on BreachForums. Software engineer Arseniy Shestakov confirmed from current and past Yandex employees that the leak is real and reflects code likely dating to the start of war in Ukraine in February 2022. That would mean that someone effectively archived this data on the day Russia invaded Ukraine and held onto it for 11 months. However, the BreachForums post said it dated back to July 2022. I found some Jupyter Notebooks in the Analysis section of Crypta that show outputs with test data dated July 2022, which would align with what the original poster suggested. Yandex confirmed the leak but denied that it was hacked, instead blaming it on a former employee, and dismissed that it was a threat to its users or performance.

Image from Bleeping Computer
At the time of writing, Yandex is still up for sale. Multiple oligarchs have expressed interest and placed bids. In June 2023, Putin approved a bid from a “consortium of billionaires” and VTB Bank, but the deal appears to have been rejected by Yandex’s board over sanctions risks, and may also have had something to do with Russian regulations reportedly requiring “foreigners selling their Russian assets to do so at a discount of at least 50 percent. The Kremlin has also imposed a new 10-percent tax on all such transactions.” As of now there are rumors that if a sale cannot be negotiated, nationalization “is a very real scenario.”
Yandex still seems to be facing internal tensions, because despite Kudrin’s role, in June Yandex was fined 2 million roubles in a Moscow court for refusing to share user information with the Federal Security Service (FSB). It will be interesting to see if that resistance changes if Putin approved buyers (or nationalization) succeed. Indeed, Meduza just reported that because of a new order signed by Russia's Prime Minister, as of September 1, 2023, Yandex will be required to provide the FSB with constant access to data related to its taxi services, many of which operate internationally. Interestingly the reporting also revealed that Yandex stores all of its global customer data in Russia and is not able to separate the Russian data from international data, and that in 2019, according to Yandex's own disclosures, it satisfied about 84% of official requests to share user data with the government.
Codebase
The code in the Yandex leak is broken down by service. It’s written in a mix of Russian and English, and reporters have also noted uses of racist language in comments. A variety of coding languages are used but primarily Python, C++, and YQL (Yandex Query Language, a flavor of SQL). The leak contained just the code, not a true git repository that would have shown version history, and a few Jupyter Notebooks with data outputs (which appear to be from test and pre-production environments). That means it is possible to say, or make an educated guess, about what the code does, but it isn’t possible to say for sure what portions of the code were actually run or are run currently. I sorted through the Metrika and Crypta source code manually, but there are several portions of Yandex code that I have not had a chance to dig into and hope to in the future.
Metrika
The server-side AppMetrica data is processed in a service called Metrika, which encompasses the data from the mobile SDK (the SDK itself is open source) and desktop analytics (Yandex Metrica).
Below are some of the raw data fields that AppMetrica logs. Remember that Yandex reportedly said that the data it collects is “non-personalised and very limited”? That does not seem to be the case. You can see in the path at the top that this selection of fields is going into something called an “anonymizer”. But nothing about this level of detail is anonymized when it gets to this point in AppMetrica’s servers, and it never truly gets effectively anonymized.

To start with, the unique identifiers at the top of the list (zoomed in below) are getting hashed. That’s nice, and theoretically anonymizing, but they’re still going to be very unique and therefore uniquely identifying (likely more so than before because of the entropy the hashing algorithm adds). This will make incoming data easy to match probabilistically with other data about this device as it comes in, because all the service has to do is hash any incoming identifiers and see if the outputs match. The ability to preserve privacy while allowing new data to be associated with existing data is a major appeal of this anonymization strategy.

AppMetrica is taking in some very precise location data. It’s not that uncommon for app analytics to take in latitude/longitude so that growth and marketing teams can see where the app is being used. What is less normal is taking in a user’s altitude, direction, and speed, which together with a timestamp, provides a disturbingly accurate picture of a user’s movements. Unless the app being used is a fitness or run tracker, or something like Pokemon Go, there aren’t a lot of use cases that justify taking in that data, let alone storing it for AppMetrica’s supposed target audience. With this information, if someone is using your app in an airplane, you could see how high it’s flying, in what direction, at what speed, and possibly predict where it’s going next. That seems like overkill for a growth and marketing team.

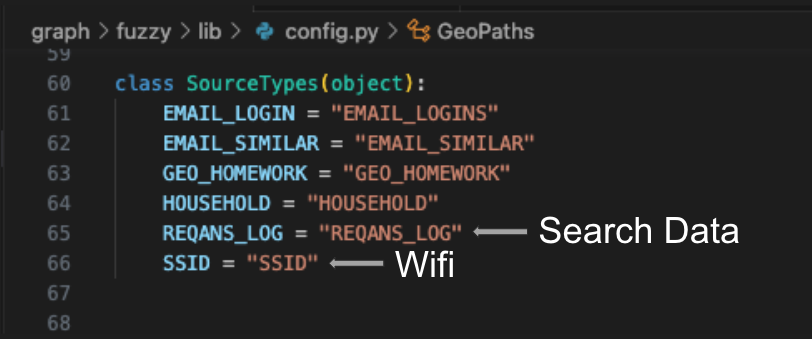
Now let’s take a quick look at how Yandex uses the wifi fields AppMetrica collects. A wifi SSID is the name of a wifi network, so if you’re connected to your home or office network right now, that would be your SSID.

Here are those same fields being used in Crypta. This process selects the `DeviceID` and `OriginalDeviceId`, and whether either of these fields are hashed or not at this point is unclear. It also selects several of the above Wifi fields, and thanks to the hashed or unhashed device id, they are attached to a unique identifier.

Here, still in Crypta, both Device ID and SSID are being matched to a Yandex ID, which will be used to associate any data corresponding to them with several other pools of data Crypta processes. One possible motive to select both fields is that an SSID might have multiple devices associated with it, which could indicate a user with multiple devices, or a household.

Moving back in the codebase to Metrika, below we have identifiers that come in through a click event, being matched with any ids, hashed two ways or unhashed, until a match is found in the system. This enables that event to be associated with the correct consumer or household. For example, it compares the plain `AndroidId`, the MD5 hash of it, and the SHA1 hash of it. The `Fingerprint` is generated using some of the raw fields seen in the first list, like `ClientIP` and `OSVersion`. Even after anonymization, this data can still be used to identify matches, which is how anonymization is supposed to work. Anonymization should preserve both privacy and functionality. However having what appears to be both hashed and unhashed data types floating around in the same tools undermines that anonymization.

As new information for a consumer comes in, user socio-demographic attributes are updated as needed. The basic attributes shown here are age band (they do have exact age in other parts of the system but it’s a nice attempt at generalizing for privacy purposes) and sex (only male or female). They are both associated with Device ID, which has to get hashed before it’s sent over the buffer, suggesting it was processed and stored unhashed, which is, again, pretty inconsistent and therefore ineffective anonymization.

Metrika also contains code related to Yandex’s Audiences product which allows users to generate segments for targeted advertising or user profiles using data from AppMetrica, Data Brokers, or uploading their own data. In the first two cases, consumers who end up in the segment don’t have to have used the customer’s product, it can be used to generate fresh leads.
Crypta
Crypta is Yandex’s behavioral analytics service, which creates demographic segments for very specific ad targeting, specifically Yandex Ads. It takes data points from all over Yandex’s services and combines it with inferences determined from analyzing behavioral data to create holistic profiles which it uses to create very specific ad segments. Part of the reason that it takes data from all over Yandex’s services is that Yandex places ads all over its services. For example, while using Yandex Navigator, if a user is stopped in traffic, Yandex will start displaying ads.

Here are some examples of the segments Crypta generates:

The Smokers segment seems to track users who purchase specific smoking products, like e-cigarettes and tobacco. Summer residents uses geolocation data to track which users have dachas (summer homes) and how often they visit them.

“Travellers” uses geolocation to track whether a user has traveled from their main region, which Crypta has already determined, to another, and classifies it as domestic or international.

Mail data appears to pull from email data to track whether a user has any boarding passes, plane tickets or hotel confirmations.

The gas station segment seems to track whether a user has visited a gas station.

If Yandex can make these segments it seems pretty plausible that anyone with access to their data could take the same data points and create a segment like “Young Men of Military Age Planning to Leave Russia” or generate segments based around vices and blackmail.
The below section appears to outline some basic machine learning model training. It seems to leverage some first party data because it knows whether a user did business at the legal office or showed up to their medical clinic appointment or bought something at the pharmacy when it tracks so-called “deep conversions”.

This is a very basic example of a household composition stored in Crypta: household id, size, gender, any elderly, any children, but of course Yandex has much more precise information than that.

Here is another example of Crypta using AppMetrica wifi data, associated with Device ID, this time tracking connection types for a segment.

AppMetrica SSIDs are being used for processing here to presumably deduplicate user records associated with a common wifi access point.


These are some examples of data pools that Crypta uses for processing for the purposes of its fuzzy matching in graphs. Crypta pulls from email login data, geolocation data for home and work locations, household data, Reqans data (which appears to be search data), and yet again, SSIDs.
This is an example of processing the email login data. Email addresses and logins are associated here with Yandex IDs. This means that once any “anonymized” data from AppMetrica is connected to a Yandex ID, Crypta can associate with email and login information, effectively reidentifying it. This is very convenient for law enforcement.

Here Crypta appears to be trying to pull every type of identifier this developer could think of.

Yandex uses a “Passport” system to create one Yandex login to rule them all, which can log you in across all Yandex apps and services. This form takes first name, last name, and phone number.

Crypta has data from Passport. Here it takes the Passport User ID and matches it to a phone number. The presence of a PASSPORT_PROFILE source type also suggests that that first and last name might be accessible as well, but I did not find any examples of that data being used by Crypta. The fact that there is a source called PASSPORT_PHONE_DUMP suggests that these phone numbers are being extracted at a large scale.

One interesting perk of having a codebase is the test data that it comes with. Here you can see a mock up of possible data from Passport for testing purposes.

Another example of processing that happens in the graphs section, is taking the latitude and longitude of a user’s predicted home, associated with that user’s Yandex ID, and plotting it on a geo graph.

Which it then uses to find and plot that user’s (actual not just k) neighbors and their Yandex IDs.

The process below shows multiple Yandex products being used by Crypta in a fairly creepy way. This screenshot is part of a very long process that involves pulling children and ages from search data based on visits to certain sites, then from AppMetrica, and from the Taxi app, and pulling it all together to create a holistic picture of how many children are in a given household.


If we zoom in on this last section you can see that once you have one kind of ID, whether it’s Household, Passport, Crypta ID, or Yandex ID, you have them all and all of the identifying data associated with them. Which, given the email addresses, phone numbers, household data, and geo data, is pretty effective for re-identification.

Crypta profiles integrate biometric data, most likely from smart speakers that use Yandex’s Alice smart assistant. This smart assistant is supposed to be able to interact appropriately with kids, like playing games or making up fairy tales.


Crypta uses biometric data to identify children and their age range by voice, to further build out the household’s profile for use in ads. That voice biometric data is presumably from the Alice product. It’s not unreasonable for a voice activated product that is supposed to interact appropriately with children to be able to identify their voices, but this isn’t within the Alice app or that function. This data is getting sent outside of that app to Crypta for behavioral analytics to generate ad segments. The section also indicates that socio-demographic data includes actual birth dates.

Crypta has code for a User Interface (UI) portal to display some of its household and user profile information. This BasicInfographicsCard shows marital status, income, has children, and three icons for interests. In case you were wondering what those interests are, below the list of available icons.


These individual profiles can be searched by Crypta or Yandex ID, suggesting that Crypta is not just aggregating these segments, but instead making it possible to search for more information on individual consumers.


This is a list of available app icons, further illustrating the breadth of data sources Yandex has available to associate with individual consumer profiles.

To further build out these profiles, Yandex appears to be able to associate all of the below identifiers to social media accounts like instagram, facebook, and VK.


Matcher
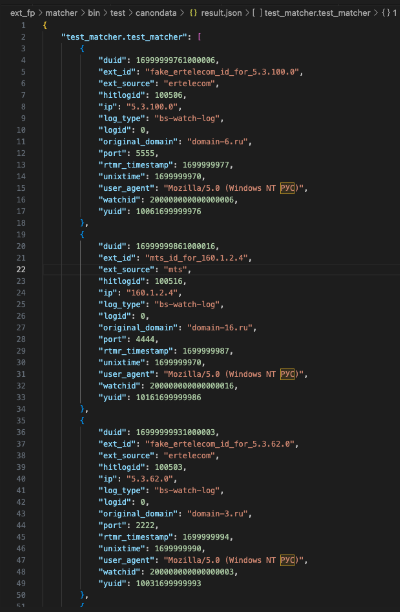
Matcher is a section of Crypta’s code that syncs fingerprinting events with four major Russian telecoms providers and Intent.ai, outside of Yandex’s own assets. One of these providers, Rostelecom, is Russian state-owned and also provides broadband service to Crimea. This means that fingerprinting events that are synced with this provider through Crypta could be accessible to parts of the Russian state.

The matcher builds a connection to Rostelecom’s API and passes in a Fingerprint Event. Rostelecom then takes the information from that fingerprint and attempts to match it to a user in its own system. If it finds a match, it returns the ID that Rostelecom has for that user.



This is a mock up for testing that shows what the result is supposed to look like. It is essentially half log event and half fingerprint, and it incorporates the new external ID and the source.
Conclusion

The AppMetrica SDKs give Yandex a very broad international reach of data subjects and Yandex has been evasive and misleading about how that data is used. While the data points collected up front are fairly disturbing, that data can say so much more about you when it’s matched and analyzed with other pre-existing data a company already has access to. Yandex makes a few gestures towards anonymization but they are ineffective because hashing isn’t used consistently, and more importantly they collect data that could easily re-identify a user and make sure it is all firmly associated (they refer to it as glueing) through a chain of ids and segments.
The matcher process is clear evidence that at least some of the data collected by Yandex could be synced with Russian state owned entities. Yandex also appears to be very, very close to becoming state controlled or nationalized, and it is about to be required to share international user data from its taxi services with the FSB.
If your company runs an app, pay attention to who runs your SDKs, what data points they may collect and where they are sending your users’ data. Yandex claimed it gets consent through the apps and that it only gets the data app developers choose to send it, throwing the blame right at its partners' doorsteps.
If you are a consumer, know that nothing is guaranteed to stay harmless forever. Maybe you trust this app with your data now, but how will you feel when that app gets sold to a company you don’t trust? Or if that company is headquartered in a country that becomes hostile to yours? Or its government starts making concerning demands to turn over user data? In theory you should be able to take your data back if you live in a jurisdiction that requires companies to respect data deletion requests, but the insights derived from that data might be considered that company's work product and not included in that deletion. In the case of the AppMetrica SDKs, you might not even realize a company has your data because they are quietly embedded in another company's app.