
Kaileigh McCrea, Privacy Engineer • 7 minute read

This is the write-up for the research I presented at DEFCON 30's Crypto & Privacy Village on August 14, 2022 in Las Vegas.
Consent string abuse is serious, but using the consent string, which is supposed to preserve a consumer’s privacy preferences, to smuggle out the payload from invasive data collection is a new level of audacity. The Interactive Advertising Bureau’s (IAB) Transparency and Consent Framework (TCF) v2.0 consent string is an encoded data structure which records information about a user’s privacy preferences to communicate them to would be trackers on a page, to ensure General Data Protection Regulation (EU) 2016/679 (GDPR) compliance in the EU. Confiant discovered a company claiming to be doing invalid traffic (IVT) detection using what appeared to be a TCF consent string to exfiltrate the data.
Voldrakus is a real case of consent string steganography Confiant caught operating at a massive scale. This campaign by a small Eastern European ad tech company targeted the Android devices of millions of users in the US and disguised the mass collection of invasive fingerprinting data, raising very concerning implications for national security, and personal data privacy and security.
Background
IAB Europe created the Transparency and Consent Framework to help ad tech standardize compliance with the EU’s GDPR. The framework leverages registered Consent Management Platforms (CMP) to display privacy notices (typically in the form of a cookie banner) to users and then record their privacy preferences in the form of a consent string when they interact with the banner. In order for an ad tech vendor to track users in a compliant way, they must first be registered as vendors with the TCF and then obtain consent or have a legitimate interest to track the user on that page. The validity of the TCF consent string is very important to the vendors operating in that context because it alerts them to the user’s privacy selections so that they know whether or not they have a legal basis for tracking. A fraudulent consent string throws the legal basis of the actions of every vendor that receives it into question, creating a chain of liability and potentially harming the user who might then be tracked without their consent. Only a registered CMP can create a valid consent string and only a registered vendor can obtain consent or legitimate interest through the TCF to track.
Overview
This incident began when the Security Team picked up a scan showing signals for heavy obfuscation and browser fingerprinting. They began to analyze and deobfuscate the code and discovered that it was building a TCF privacy consent string.

The Privacy Team then got involved and together we analyzed the output consent string. It is longer than average, and lacks some typical segmentation, but on the surface it looks fairly convincing. The string decoded successfully in the TCF Consent String Decoder, but into an invalid consent string. It referenced purposes, vendors, and version numbers that did not exist in the TCF. Indeed, the entity that was creating this consent string was not a registered CMP and therefore no consent string that they created could have been considered valid. There was no code to provide notice to a user or interact with a user to record privacy preferences. It quickly became clear that coding a valid consent string was not the primary goal of creating this data structure.
Making matters even more odd was the fact that this operation was found on several scans, none of which were in the EU jurisdiction where GDPR compliance, and therefore the TCF, would have been required. It seemed to be confined to the US, occasionally occurring in California where the IAB’s US Privacy framework for California Consumer Privacy Act of 2018 (CCPA) compliance would have been necessary. The US Privacy framework uses a much simpler four character string that requires no encoding to record privacy preferences, and there was no mistaking this extremely long and high entropy encoded string for a US Privacy consent string. This left us wondering why this entity would even bother to create an imitation consent string at all?

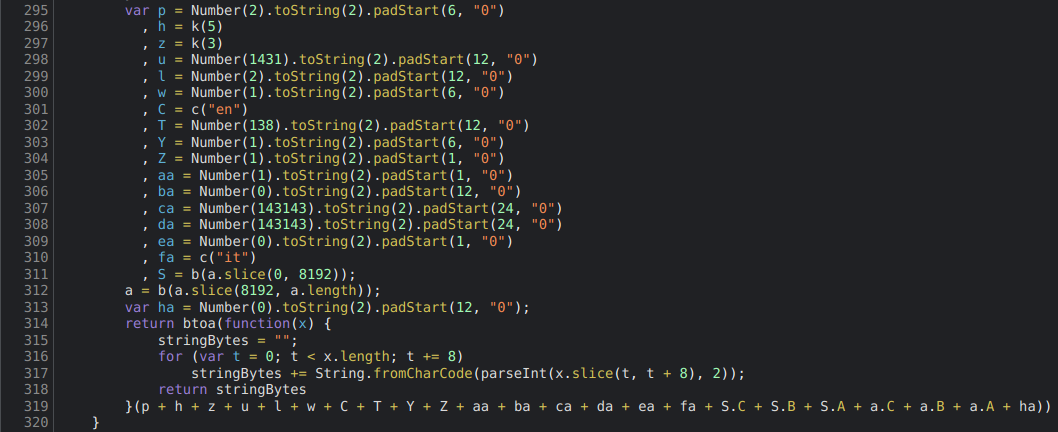
{"core": {"version": 2,"created": 1642874948800, # Today minus 5 days 🚩"lastUpdated": 1643047748800, # Today minus 3 days 🚩"cmpId": 1431, # This ID doesn't exist! 🚩"cmpVersion": 2,"consentScreen": 1,"consentLanguage": "EN", # Hardcoded 🚩"vendorListVersion": 138, # Most recent one is 136 🚩"policyVersion": 1,"isServiceSpecified": true,"useNonStandardStacks": true,"specialFeatureOptins": {},"purposeConsents": {[...] # Contains IDs that don't exist 🚩},"purposeLegitimateInterests": {[...] # Contains IDs that don't exist 🚩},"purposeOneTreatment": false,"publisherCountryCode": "IT", # Hardcoded 🚩"vendorConsents": {[...] # Encodes the fingerprinting data
We began to reverse engineer the consent string and eventually discovered its real purpose. This fraudulent consent string was being used to disguise the un-hashed payload from the browser fingerprinting which had initially been flagged in the code. The encoded payload could then be sent back to this company’s servers using a GDPR privacy param, and in later cases, the US Privacy param.

Browser Fingerprinting
Browser fingerprinting is the technique of collecting any combination of settings and attributes of a user's browser, like the user agent string and screen width. That data is then in most cases used to probabilistically identify that same user across applications and devices, but it can also be used for bot detection. Typically the data is collected for the sake of adding entropy (randomness) to the dataset before it is hashed into a fingerprint (a compressed high entropy string of numbers and characters) that can then be used as a unique identifier. However, sometimes that data is simply collected and stored in a data object in its raw form, and that data might be sent back to that entity's servers without being hashed.
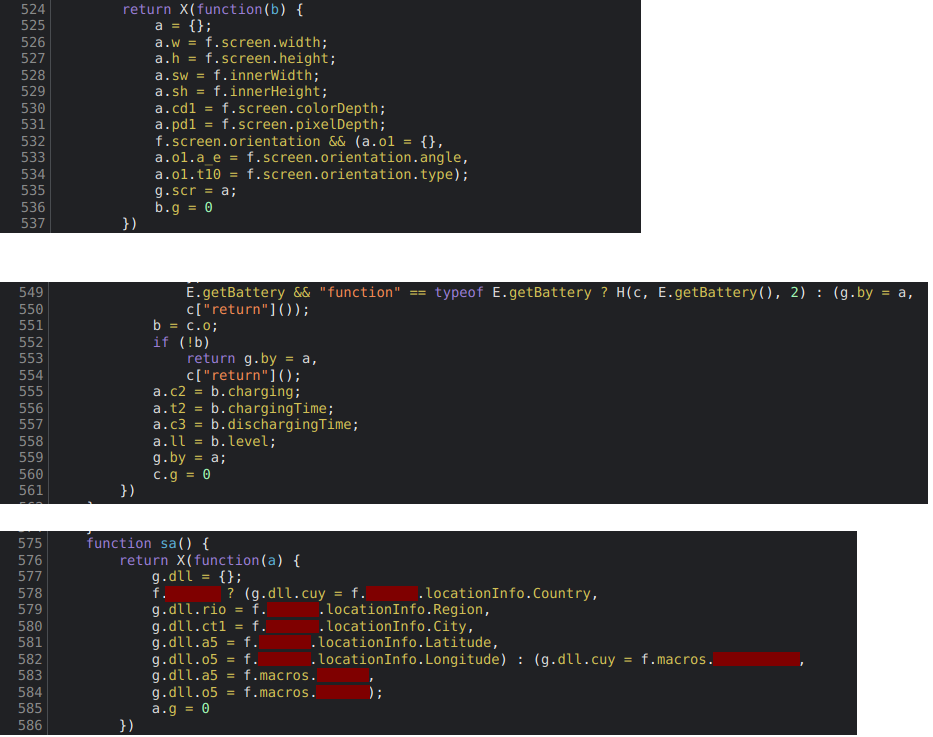
The browser fingerprinting that this entity performed and hid in this consent string operated at a pretty invasive level. In addition to collecting the user string and geolocation, it looked at Device Motion events and the Battery Level. This is the kind of data that, at scale, heat maps could be generated from. Instead of hashing the data into a typical fingerprint, which would be more secure and efficient, they created a process to encode it into the long consent string structure that we discovered and transmitted the data server side using a param that was designed for the TCF framework’s privacy signals.
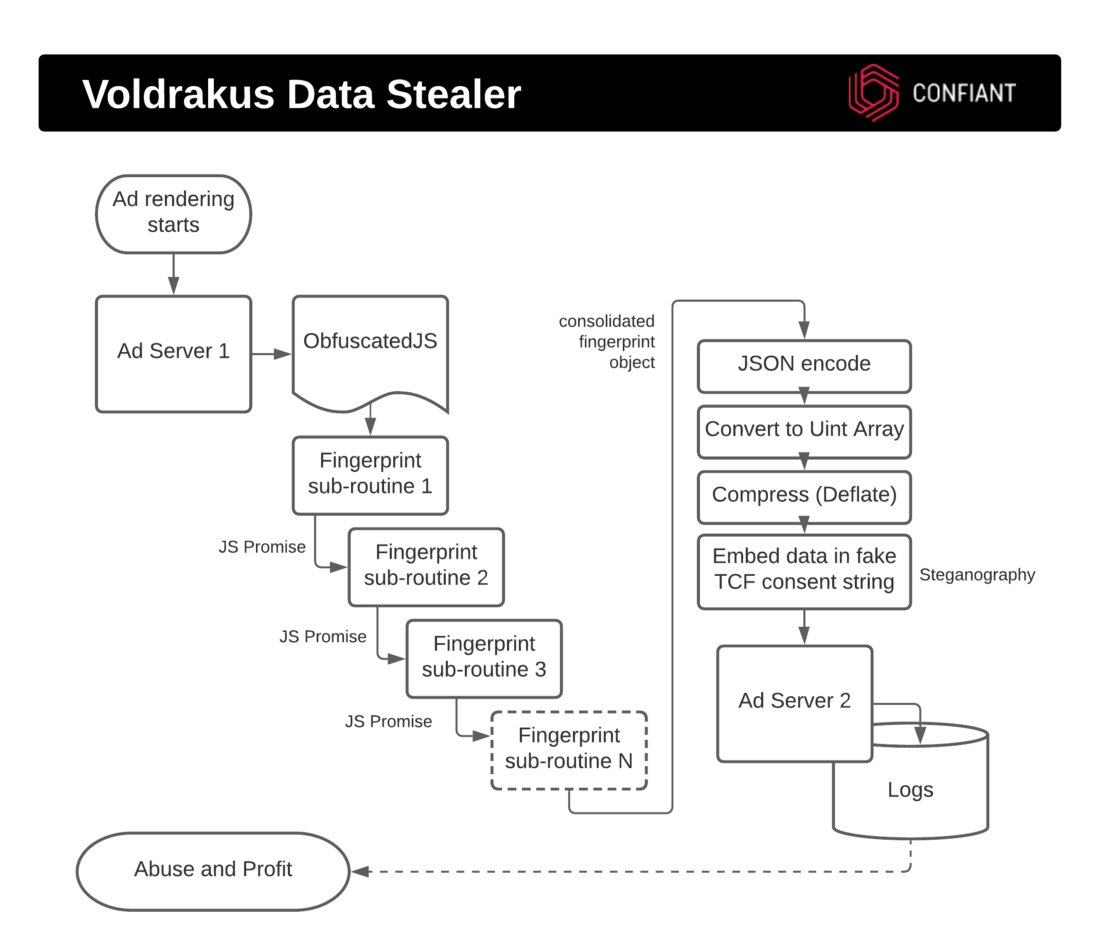
Putting it All Together
This campaign targeted Android users in the US at a very high volume; we estimate the scale to be in the millions. It collected invasive fingerprinting data, like geolocation, device motion, and battery level. This privacy invasive payload was encoded (but never hashed) to look like a decodable TCF GDPR privacy consent string, and then sent back to this entity’s servers using a “gdpr_consent” parameter. The entity that did this is a small Eastern European digital marketing agency. They are not registered with TCF as a CMP or a Vendor, and have no legal basis to be making consent strings, nor are they collecting consent from the users they collect data from. The US is not even a GDPR jurisdiction. A few times this actor did switch things up and use the “us_privacy” parameter to pass this same consent string, in California, which is currently the only IAB US Privacy framework jurisdiction. The data collection, while invasive and concerning, is not itself illegal. What takes this campaign into red flag territory is the entity’s decision to heavily obfuscate both the code itself and the data payload and to abuse a privacy framework to exfiltrate the data. Had they simply hashed the data or sent the data to their servers using any other parameter, this might have slipped under the radar.
Obfuscation
If this strategy was for something credible like IVT detection or security, then why would it require so many layers of disguise? In addition to some encoded keywords, to make inspection more difficult, the code breaks the logic flow by running subroutines in JavaScript promises. In the end, this is just testing the analyst’s patience as the logic is linear at a high level. This gives us a hint that the code was written in TypeScript as it is using generators.
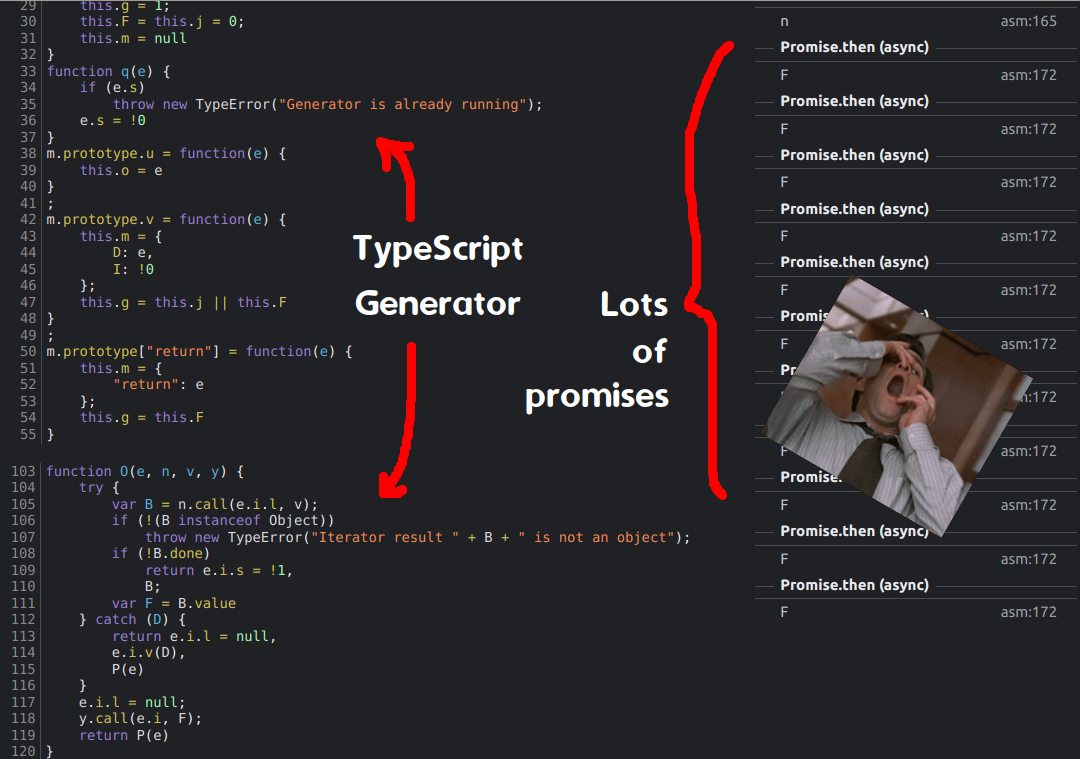
The async/await promise structure contained browser fingerprinting subroutines which were collected into an object. For an introduction to this topic, Confiant has written multiple articles, starting with Eliya’s article “How Malvertisers Weaponize Device Fingerprinting” in 2018. The object would then be JSON encoded and then converted into a Uint array before being compressed and then embedded into the fake consent string structure.
We now know that the purpose of creating this fake consent string itself was also obfuscation, to disguise the nature of its payload. The fake consent string is then inappropriately exfiltrated using a privacy consent param. In the below screenshot, hardcoded values that later appear in the decoded consent string can be seen, like the "en" consentLanguage value and the "it" publisherCountryCode value
Steganography
Steganography is the practice of hiding one kind of information inside another. In this case, the browser fingerprinting payload is hidden inside a data structure that was designed to pass for an IAB TCF consent string. The same input, the consent string, can be decoded in two different ways to reveal two different outputs. It decodes into a TCF consent string, although that string does not contain valid consent data, but it also decodes into the browser fingerprinting payload that was its true purpose to conceal.
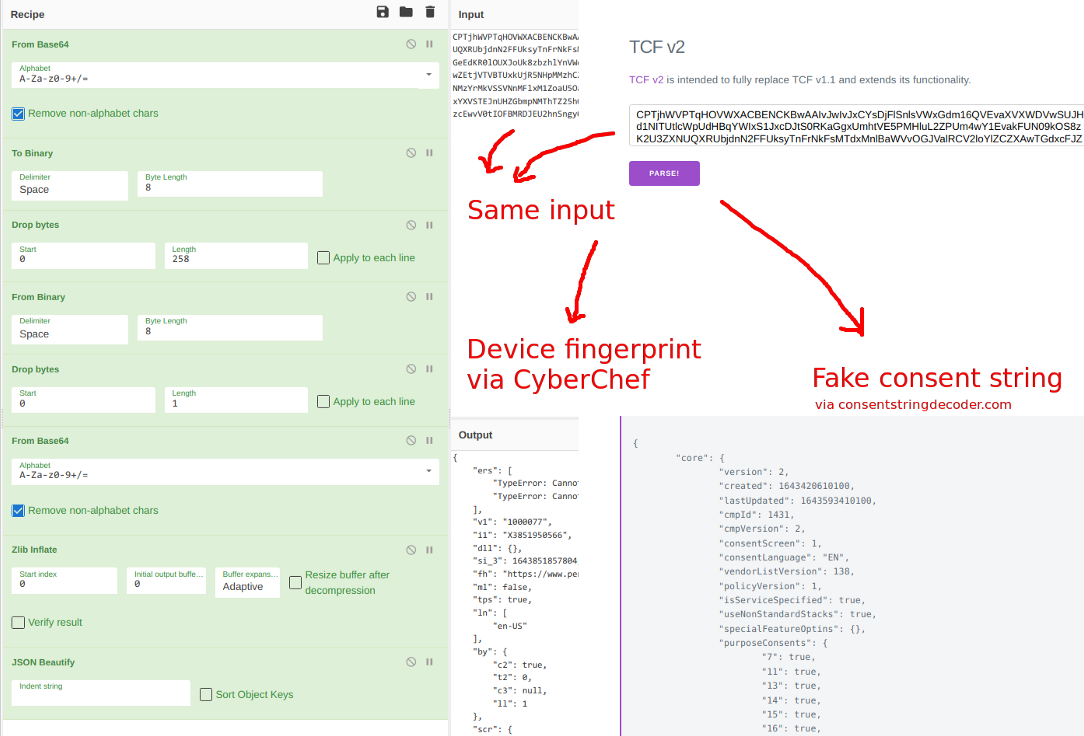
Possible Objectives
If the fingerprinting were legitimate, why not use a normal hashing algorithm to protect the data and why use so much process obfuscation? If it is for security or anti-fraud, why not do the actual filtering and blocking client-side and without misusing privacy frameworks?
The obfuscation first and foremost clearly disguises a massive campaign of data collection. This process could be used for recon to target delivery of future projects: like spyware and malware, or ads containing scams or misinformation. A process like this could be used by foreign entities to collect intelligence on Americans. In fact, that is exactly what is happening here although we have found no evidence of a nation state actor behind this. This could just be a large dataset on sale somewhere for anybody’s use, containing the kind of information that could generate a heat map. A nation state doesn't need to build an intelligence gathering operation if it can simply buy the data through a data broker and these same datasets may be leveraged by law enforcement. Datasets like this could even be used to find and target an even more specific group or individual.
Conclusion
It takes a lot of audacity to leverage a privacy framework to perform and disguise invasive data collection. At minimum this tactic was unnecessary, incredibly disrespectful, and unethical. While we do not know for certain what they did with this data, a foreign entity conducting a massive data collection operation on millions of devices in the US has a number of concerning possible law enforcement and national security implications.
This is the second case of consent string abuse that we have published research on this year. Prior to these publications no concrete cases like these had been documented in the wild and while the TCF framework is still fairly new, that was not for a lack of searching by researchers. As consent strings are becoming a better known part of the browser landscape, it seems clear that they are becoming better known targets for abuse as well. The IAB’s TCF will soon be replaced with the newer Global Privacy Platform (GPP), which may have its own consent string structure, and we would expect the TCF in its current form to remain for some time for backwards compatibility purposes. However, a backwards compatibility solution is rarely well-monitored and could become an even more appealing target for abuse, in a landscape where that abuse is already accelerating.